ディープラーニングでアフターコーディングを省力化~データサイエンスを知るコラム④
はじめに
本コラムでは、弊社で取り組んでいる、自然言語処理技術を利用した事例をご紹介します。
弊社では市場調査の一環で、日々多くのアンケート調査を行っています。アンケート調査した結果のうち、回答者自身に文章や単語を記入して答えていただいた自由回答データは、類似回答ごとにカテゴリを付与して集計することが一般的です。カテゴリを付与する作業を「アフターコーディング」と呼びます。
アフターコーディングの実施には大きな労力がかかります。そこで近年発展の目覚ましいディープラーニングモデルの力でアフターコーディングを効率化する取り組みを始めました。
使用するアンケートデータについて
本コラムで例として用いるアンケートデータについてご説明します。用いるデータは、弊社とQualtrics社が共同企画で行ったアンケートの内、「コロナウイルスに伴い、勤務先からの支援として増えたもの」を尋ねた設問の回答データです。このアンケートは2020年4月21日から5月15日にかけて、当時緊急事態宣言が発出された都道府県(東京、埼玉、千葉、神奈川、大阪、兵庫、福岡)の被雇用者を対象に、「全国の労働者の実体と意識の変化などを明らかにし、今後の労働環境の改善の一助とする」ことを目的として実施されました。この設問では約13000件の回答を得ましたが、このコラムではそのうちの一部のみを扱います。
このアンケートの自由回答とアフターコーディング後のカテゴリの例を図表1に示します。
図表1

アフターコーディングという作業、人の目で全回答を見てカテゴリを付与しなければならないため、実施には大きな労力がかかります。そこでアフターコーディングをディープラーニングモデルの力で効率化する取り組みを始めました。
学習データの用意が必要
アフターコーディングを効率化というと、自由回答データを入力するだけで、自動的に付与するカテゴリを予測できたら理想に思えます。しかしそれを実現することは難しいため、ここでは何件か自由回答とカテゴリの例(学習データ)を用意し、予測モデルに学習させた上で、未知の自由回答に対してカテゴリを予測することとします。学習データなしの予測が難しい理由には、アフターコーディングの潜在的な特性が関わっています。
一般にアンケートは何らかの目的のもと実施され、それに応じて付与すべきカテゴリが変わります。極端な例ですが、「勤務先からの支援の有無の調査」が目的ならば、「有り」または「無し」の2カテゴリにアフターコーディングすれば十分でしょう。そうではなく「勤務先からの支援内容の調査」が目的なら、支援内容ごとにカテゴリを作ってアフターコーディングするべきです。このように、カテゴリを付与する基準は目的によるため、自由回答データのみから判断することは難しいです。
よって、ここでは学習データとして、「自由回答」と「カテゴリ」の例を用意し学習させ、その後未知の自由回答に対してカテゴリを予測するシステムを構築します。

予測手法
アフターコーディングを予測するために用いる手法についてご紹介します。
●形態素解析による前処理
機械学習で自然言語を扱う際には、字句解析(*1)して扱いやすい形にしてから分析することが一般的です。今回の予測でも、自由回答データを字句解析することから始めます。
字句解析には、JUMAN++(*2)やMeCab(*3)などを用いて形態素解析(*4)する方法や、文字の並び順を参考に文字を分割するN-gram, 文に現れた頻度を参考に文字を分割するSentencePieceなどの方法があります。それぞれ長所短所がありますが、今回はJUMAN++による形態素解析を行います。JUMAN++は文字の表記に柔軟に対応できるため、自由回答データの形態素解析に適していると考えました。
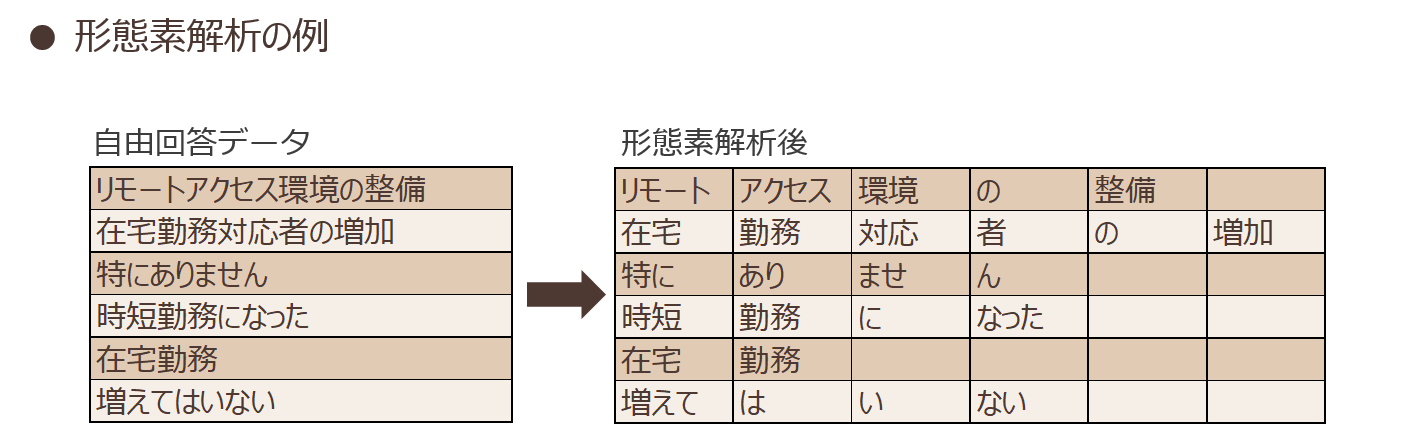
図表2に、実際に形態素解析した一例を示します。
図表2
●BERTと多クラス分類ロジスティック回帰による予測
字句解析したデータを基に、アフターコーディング結果を予測する手法について説明します。
今回は、字句解析したデータをBERTというディープラーニングモデルに入力した後、得られた特徴量ベクトルに多クラス分類ロジスティック回帰を適用して、カテゴリを予測します。
BERTは自然言語処理に特化したディープラーニングモデルです。2018年10月にGoogleから発表され、いくつものタスクで最先端の結果を残しました。BERTは双方向のTransformer(*5)を用いることで、前後の文脈について効率的に学習することができることが特徴です。また、BERTでは大量の文章データを事前学習することで、汎用的に適用できる単語や文章の特徴を学習し、様々なタスクに適用することができます。本コラムで扱うカテゴリの予測では、学習データを少量しか用意できないため、単語の特徴を一から学習することは困難ですが、BERTの学習済みモデルを使うことで、汎用的な特徴を生かして上手く予測できる可能性があります。
BERTから得られた特徴量を、mean pooling(*6)して768次元のベクトルに縮約した後、多クラス分類ロジスティック回帰を行うことで、アフターコーディング結果を予測します。
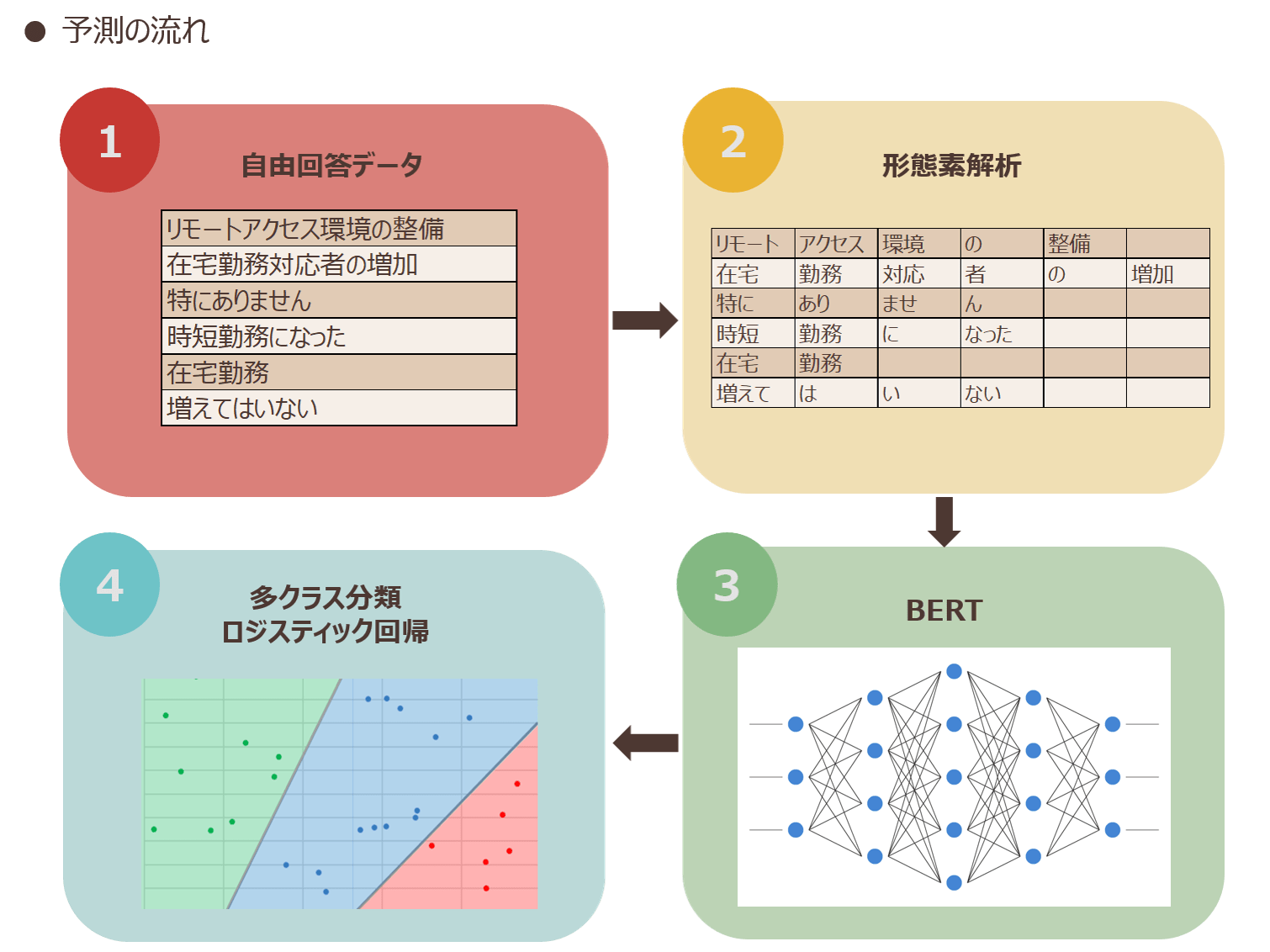
ディープラーニングというと実行に時間がかかる印象ですが、本システムではディープラーニングモデルの再学習は行わず特徴量の生成に使うのみなので、比較的軽量に実行することができます。図表3にシステムの予測の流れを示します。
図表3
●API化してEXCELと連携
上記の予測するシステムをWeb API(*7)にすることで、予測含むアフターコーディングの全てをExcel上で行えるようにしてみました。
このシステムは、アンケートに関わる弊社社員に使ってもらうことを想定しています。そのため関数やショートカットキーなどの操作に慣れているExcel上で操作してもらうことが、導入の障壁を下げ、効率よくアフターコーディングすることに繋がると考えました。
実際に予測
今回はBERTを事前に訓練したモデルとして、国立研究開発法人情報通信研究機構(NICT)によって公開されているモデル(*8)を使用します。こちらのモデルでは、事前学習に日本語Wikipedia全件データ(タイトル除く)を利用しています。
●予測精度
検証用に、アンケートデータを10カテゴリにアフターコーディングしました。そのうち各カテゴリ50件ずつ計500件のデータを抽出します。500件の内、各カテゴリ40件ずつの計400件を学習データ、残りの100件をテストデータとして予測精度を検証します。
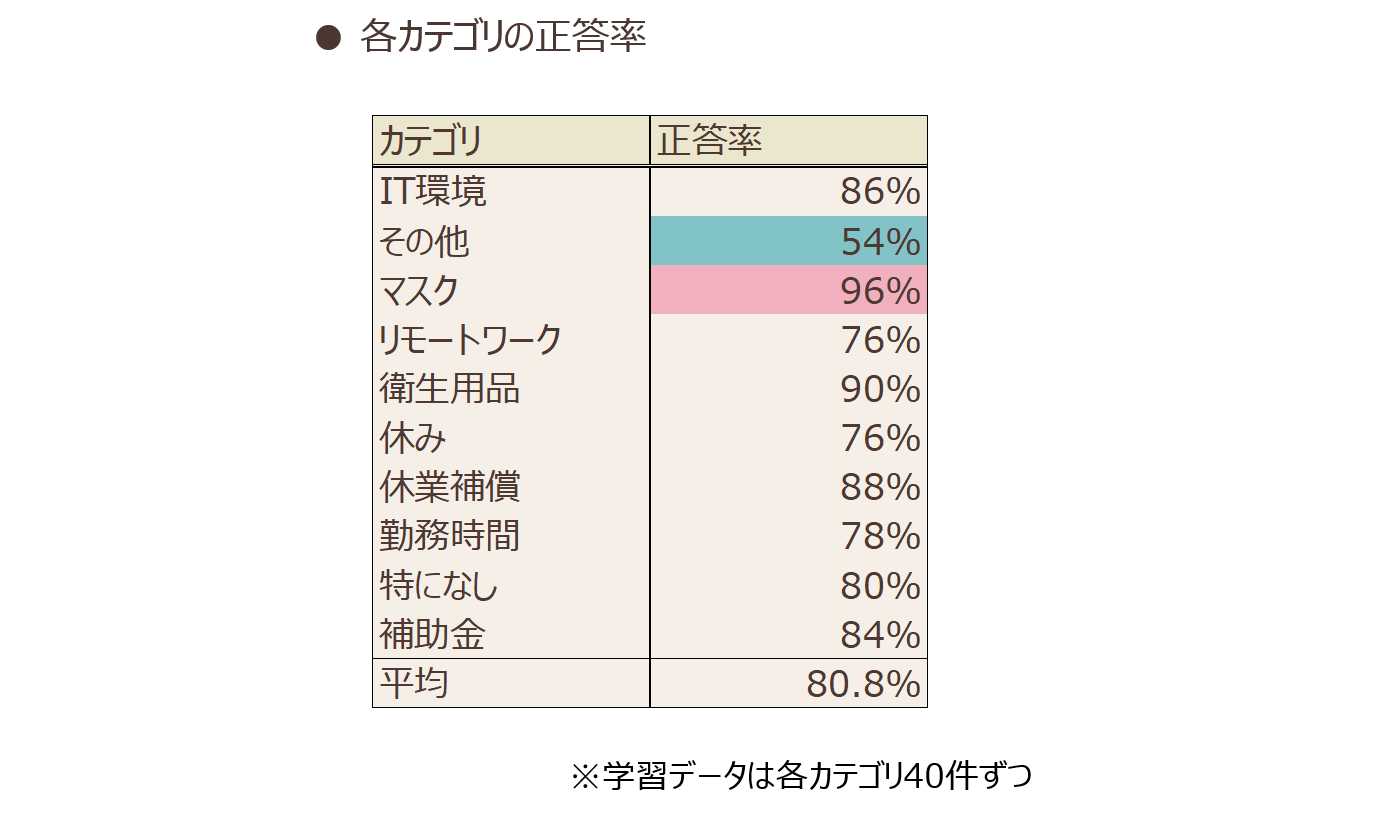
学習データを入れ替えながら5回の交差検証(*9)を行い、平均正答率は80.8%でした。図表4、図表5に各カテゴリの正答率と予測した結果の一部を示します。
図表4
図表5
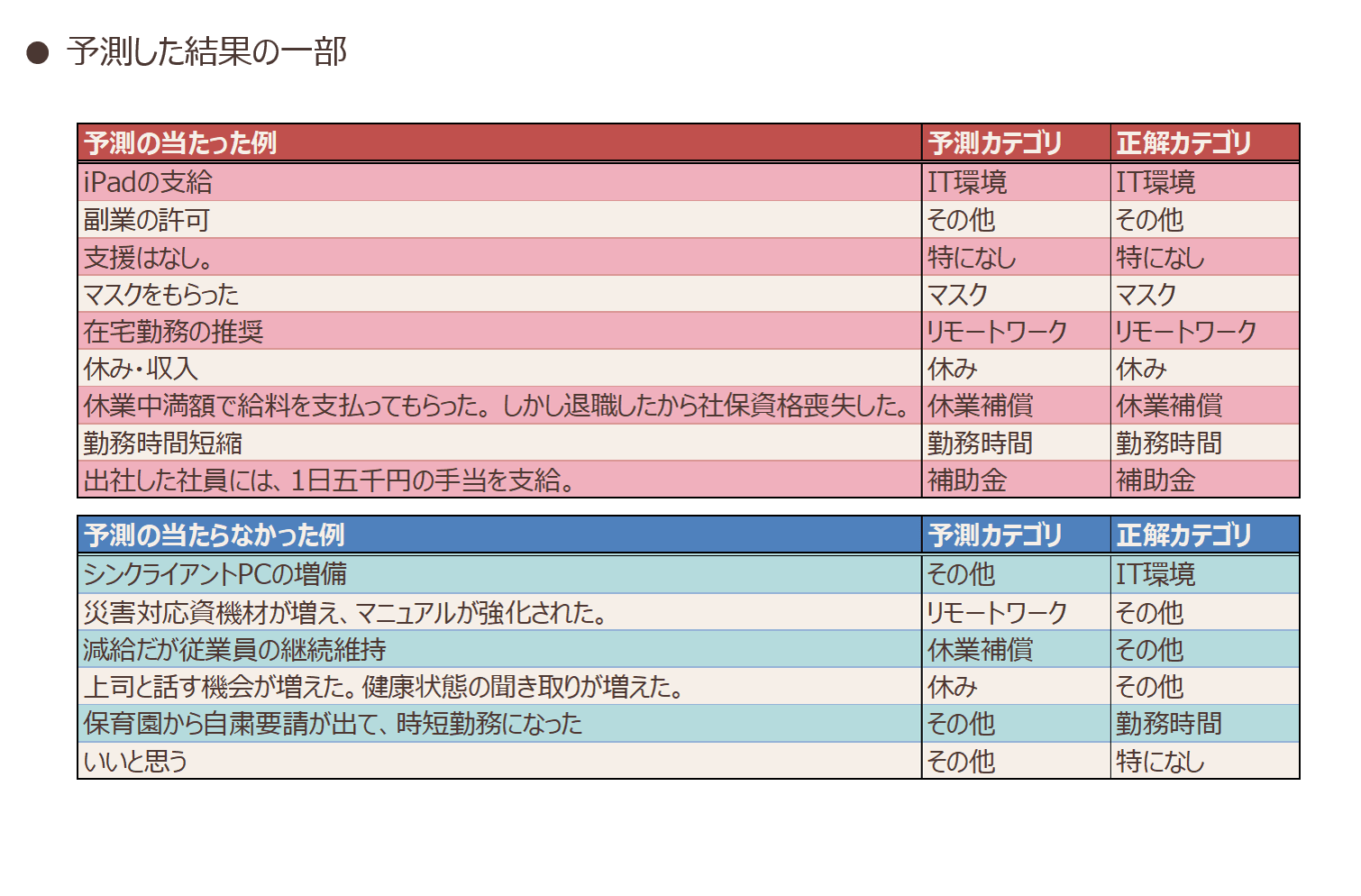
カテゴリごとの正答率を確認してみると、「その他」カテゴリを除いて、特段予測精度の低いカテゴリはありませんでした。特に「マスク」カテゴリは96%と正答率が高く、「マスク」カテゴリが付与されていた回答を確認してみると高確率で「マスク」という単語が含まれていました。カテゴリを付与する基準が明確であるため、予測精度が高かった可能性があります。逆に54%と正答率の低い「その他」カテゴリが付与されていた回答を確認してみると、こちらの元の文章にはこれといって同じ単語は含まれていませんでした。
アフターコーディングではカテゴリを細分化しすぎると、人間がカテゴリを管理できなくなったり、集計に適さない形になったりしてしまうため、回答の一部を「その他」カテゴリとしてまとめることが一般的です。これは仮説ですが、機械にとっては、普通のカテゴリと「その他」カテゴリとの分別基準がわかりづらく、予測に失敗した可能性があります。
総じて正答率は80.8%…。それなりに当たってはいますが、予測結果をそのまま正しいカテゴリとして採用することはできない精度です…。運用する際には、予測結果を人間が確認し、修正した上で採用する必要があるでしょう。
とはいえ、実はこの精度は想定内でした。人間の修正なしのカテゴリ付与はできなくとも、予測結果を元に、効率的にアフターコーディングを進めることはできないでしょうか。今回はExcel上でアフターコーディングを完結させられるよう設計したので、このシステムを使ってアフターコーディングを進めた使用感についてご紹介します。
●使用感
使用感を確かめるにあたり、以下の手順でアフターコーディングを進めます。
まず自由回答データを何件か手動でアフターコーディングします。そしてアフターコーディング済み部分を学習データとして、まだアフターコーディングを済ませていないデータのカテゴリを予測します。予測した結果を参考に、手動のアフターコーディングを進め、ある程度進んだら増えた学習データで、より高い精度の予測をします。このサイクルを繰り返して、アフターコーディングを進めます。以下にExcelシート上で使った例を図表6に示します。
図表6
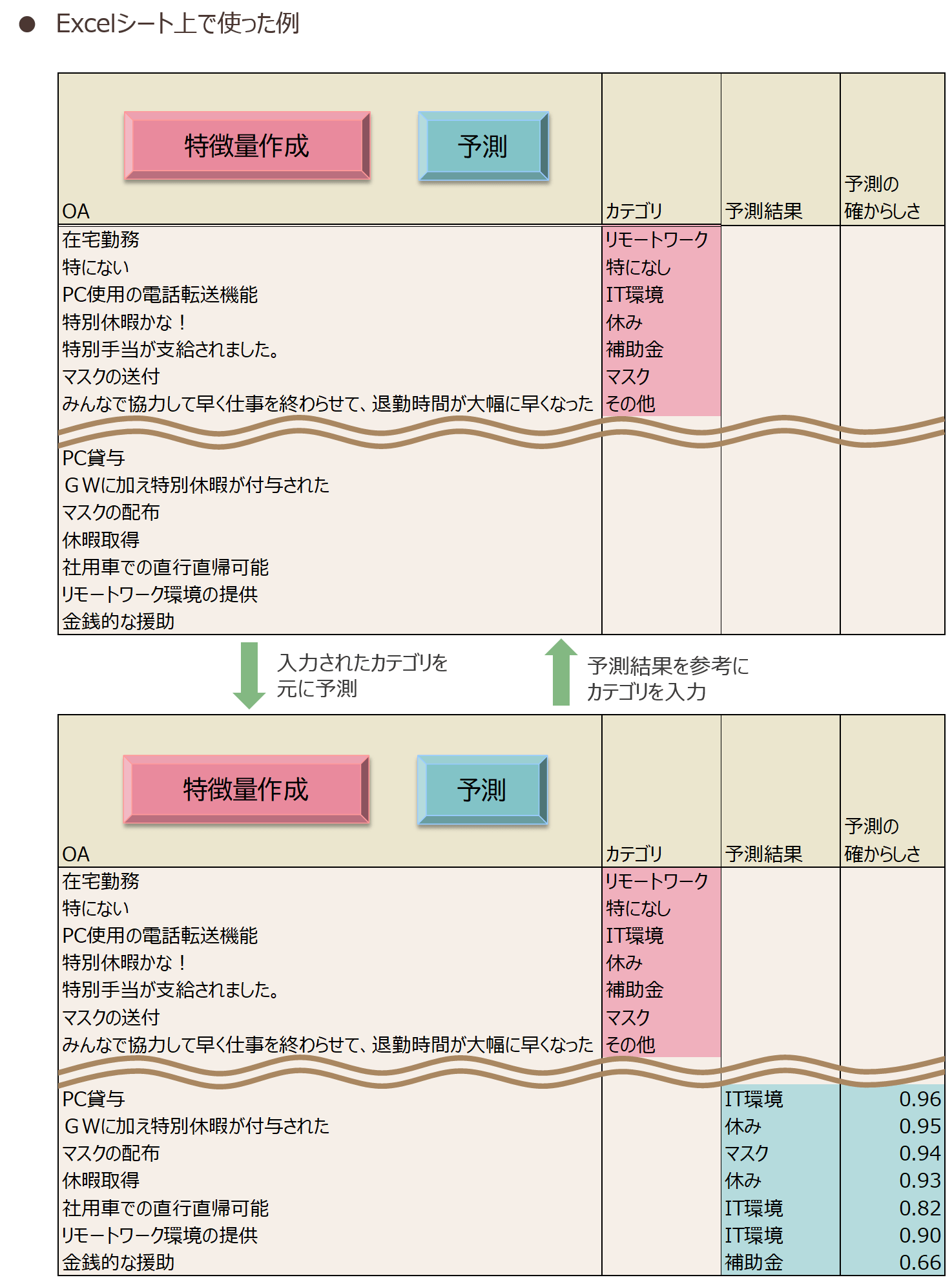
上記の手順で進めてみたところ、効率的にアフターコーディングを進めることができました。ディープラーニングモデルの再学習は行わないように予測モデルを設計したため、数秒でこまめに再度予測でき、使い勝手が良かったです。
また、カテゴリを予測する最終部分には多クラス分類ロジスティック回帰を使っているため、予測結果と合わせてその予測の確からしさ(*10)も表示するようにしてみました。予測の確からしさの高いものに注目してみると、かなりの精度で正答していることを確認できました。全体の予測精度は80.8%でしたが、予測の確からしいものにの高いものに限れば、そのままアフターコーディング結果とすることも可能でした。
まとめ
このコラムでは、弊社で取り組んでいる、アフターコーディングを効率化する試みをご紹介しました。
実装した手法での予測精度は80.8%と悪くはないものの、人間の修正なしにアフターコーディングを自動化するのは難しい結果でした。しかし別のアプローチとして、Excel上から予測できるようにしてアフターコーディングを効率的に行うシステムとして試してみたところ、効率よくアフターコーディングを進めることができました。このシステムは現在、社内で自由に利用可能な環境に設置し、社員にテスト利用しています。コラム内では深く触れませんでしたが、APIを動作させるサーバー費なども加味して、安価で運用できるようシステムを設計しています。
弊社では、多くのアンケートを実施しています。アフターコーディングに限らず、自然言語処理を使った効率化に今後とも力を入れていく予定です。
注釈
*1 字句解析:本コラムでは、何らかの手法に基づき、文章を小さな文字の塊に切り分けることを字句解析と呼んでいます。
*2 JUMAN++:京都大学黒橋・河原研究室で開発されている、日本語の形態素解析システム。内部でRNN(Recurrent Neural Network)を用いており、単語の並びの意味的な自然さを考慮した解析を行えることが特徴です。
*3 MeCab:工藤拓氏によって開発された日本語の形態素解析システム。ディープラーニングモデルを用いていないため、比較的軽量に形態素解析を行うことができます。
*4 形態素解析:形態素解析は、テキストデータを形態素(意味を持つ最小の言語単位)に分割し、それぞれの品詞等を判別する作業です。
*5 Transformer:前の層に注目する機構であるAttentionのみから成るディープラーニングモデル。従来のRNNやCNNを組み合わせたモデルと比較して、計算量が大幅に小さく並列化も可能、その上精度でも発表当時最先端を記録しました。
*6 mean pooling:poolingとは、機械学習において、パラメータを縮約する処理を指します。今回はBERT(BASEモデル)から得られた、入力トークン(形態素解析した結果の塊をBERT入力用に加工したもの)数×768次元ベクトルを、768次元ごとに平均値を取ることで、768次元のベクトルに縮約するmean poolingを施しました。膨大に増えたパラメータを縮約されて扱いやすくなります。
*7 Web API:Web Application Programming Interfaceの略。HTTPプロトコルを用いて、ネットワーク越しに利用できるサービスを提供するインターフェース、およびそのサービスを提供するシステムのことを指します。
*8 交差検証:モデルの汎化性能を評価する統計的な手法です。今回行った5回の交差検証では、データ500件のうち、テストデータ100件をそれぞれ違うデータに設定して、5回の予測を行いました。
*9 こちらのページで公開されているBPEなしBERT(BASE)モデルを使用しています。https://alaginrc.nict.go.jp/nict-bert/index.html*10 予測の確からしさ:ここでは多クラス分類ロジスティック回帰でsoftmaxを適用した後の各カテゴリの値を提示しています。
関連サービス
インテージのデータ解析・予測サービス
最新のデータサイエンス技術と独自データを活用し、予測や最適化シミュレーションなど高度なデータ活用を実現します。
著者プロフィール

転載・引用について
◆本レポートの著作権は、株式会社インテージが保有します。
下記の禁止事項・注意点を確認の上、転載・引用の際は出典を明記ください 。
「出典:インテージ 「知るギャラリー」●年●月●日公開記事」
◆禁止事項:
・内容の一部または全部の改変
・内容の一部または全部の販売・出版
・公序良俗に反する利用や違法行為につながる利用
・企業・商品・サービスの宣伝・販促を目的としたパネルデータ(*)の転載・引用
(*パネルデータ:「SRI+」「SCI」「SLI」「キッチンダイアリー」「Car-kit」「MAT-kit」「Media Gauge」「i-SSP」など)
◆その他注意点:
・本レポートを利用することにより生じたいかなるトラブル、損失、損害等について、当社は一切の責任を負いません
・この利用ルールは、著作権法上認められている引用などの利用について、制限するものではありません
◆転載・引用についてのお問い合わせはこちら





