

この【データサイエンスを知るコラム】は、インテージのデータサイエンティストが、最新技術やマーケティングへの活用可能性などを解説するコラムです。
第1回はシニアデータサイエンティストの伊藤友治が2019年度人工知能学会全国大会のレポートをお届けします。
こんにちは、インテージ先端技術部の伊藤です。【データサイエンスを知るコラム】第1回は2019年6月4日~7日にかけて新潟県新潟市で開催された『2019年度人工知能学会全国大会(JSAI)』の参加レポートをご紹介します!弊社からは私を含めて4名が参加しており、うち2名は今年の新入社員でした。先進的な取り組み内容を多分に見聞きすることができたため、皆にとって刺激的な4日間でしたが、今回のコラムでは私が代表して所感をまとめていきたいと思います。
人工知能学会は情報工学系では国内最大級の学会で、今年は事前申し込み枠が期限よりも早く打ち切られるほど参加者が集まったようです。参加者の顔ぶれは学生だけでなく社会人も多く、年齢層も広い印象でした。また、学会の内容以外にも開催地は重要で、今年は新潟開催(タレカツ、笹団子)でしたが、来年は熊本開催(桜肉、いきなり団子)です。楽しみですね。

【左】開催地の朱鷺メッセ。この先には佐渡航路があります。金山はロマンですね。
【右】タレカツ!東京では食べる機会の少ない食感と味!キャベツは贖罪。
様々なテーマに沿って同時に10以上のセッションが並行的に進められるほど規模が大きいものでした。今回は最近弊社でも取り組み始めている画像解析に関わる”画像とAIセッション”へ参加してきましたが、注目度が高いテーマなせいか常に立ち見が発生するセッションでした。また、企業ブースには主にIT系の協賛企業が多数出展しており、理論をゴリゴリ説明しているところや最新の自社サービスを紹介している企業まで様々でした。

【左】セッション会場、【右】企業ブース
本題の前に少し紹介させてください。弊社はマーケティングリサーチ(※1)をしている会社であり、ID-POSや個人メディア視聴履歴(※2)等様々なデータを保有しております。ここ数年、ディープラーニングを代表とする最先端の機械学習技術活用のアプローチを進めており、大量のテキストや画像を用いて、これまでにない価値を提供しています(この取り組み内容は次回のコラムにてご紹介します)。今回のコラムでは、その中でも弊社として力を入れており、また世の中的にも急速に発展してきている画像の領域から、セッション内容の面白さや活用の可能性についてお伝えしていきます。
さて、今回の人工知能学会全国大会からお届けするテーマは、“画像とAI”セッションの中で発表された”Between-class Learning for Image Classification”です。この論文ではディープラーニングを用いた画像分類(※3)の精度向上における新しい手法が提案されております。この手法は弊社の取り組みに対しても一定の向上効果をもたらしてくれるのではないかと期待しています。
ディープラーニングが隆盛してから多くのCNN(※4)が提案されてきましたが、CNNの構造は適切に画像の特徴量を表現できるかに関わってくるため、どのような構造を持たせるかは重要です。例えば、VGG16やAlexnet等々ありますが、近年ではResNetやSENet、NASNetが精度の高いCNNとして名前が知られています。他にも、data augmentation(※5) / drop out(※6) / batch normalization(※7)などの正則化の手法も組み合わせることで、より精度の高い、かつ汎化性能(※8)の高いモデルが生み出されてきました。今回ご紹介する論文ではこれら以外で精度を向上させる方法として、音声データを対象に精度向上を果たした過去論文(※9)の手法を、画像データにも応用展開した事例が紹介されています。この過去論文では音声データの分類タスクにおいて、ディープラーニングが人間の認識レベルを超えることができたと紹介されているのですが、実は画像データでも同様に精度向上させることができたというのが主旨になります。検証にはImageNet(※10)やCIFAR-10(※11)のデータを使用しています。
通常のCNNを用いた分類タスクのアプローチでは、分類したい複数クラスのデータ群を入力画像とし、目的変数はOne-hot label(※12)にすることで、クラス分類するCNNを学習させていきます。しかし、本論文のアプローチでは別クラス同士の入力画像を任意の割合で合成し(例えば、Aクラスのデータ:Bクラスのデータ=0.7:0.3)、目的変数もその割合に変化させて(Aクラス:0.7、Bクラス:0.3。通常とは違いOne-hotではない)、CNNを学習させていきます(Fig. 1)。実際に別クラスの画像を合成しても、Fig. 1のように人間にとっては意味のわからない画像になってしまいますね。でも、どうやら人間にとっては意味のわからない画像であっても、CNNのような機械にとっては意味のある画像として処理されるようで、2~3パーセント程度の精度向上に繋がったとのことです。他にも数値化した画像データに対して正規化(※13)もすることで、より精度の高いモデルを開発することができたとのことです。
この考え方の面白いところは、特定のCNNの構造に依存せず、様々な構造のCNNの分類性能を改善することができるという点にあります。今後も多様なCNNが生み出されていくと思いますが、いずれの手法においてもこの手法を使うことができるため、汎用的に使うことができる点が優れているようです。
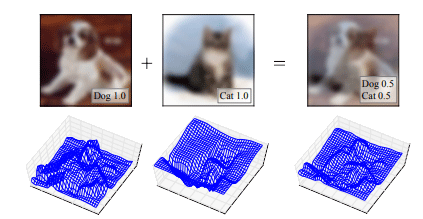
Fig. 1 画像データの合成イメージ
犬と猫の画像を用意して、それぞれを半々で合成すると右側の図のような画像ができあがります。犬?猫?どちらに見えますか?難しいところですが、人間にとっては意味のわからない画像ですよね。しかし、この画像を犬:0.5、猫:0.5として機械に教えると、分類精度が向上するのです…!
※引用元:https://arxiv.org/abs/1711.10284
具体的な学習結果の様子はFig. 2のイメージですが、CNNが抽出した特徴量(※14)の空間的な配置が通常の手法を用いると左側の図よりもクラス内(AとBのそれぞれの固まり)でより集約され、クラス間ではより離れていることがわかります。合成された画像データの特徴量は、Fig. 2の右上図のマゼンタのような位置にあり、AクラスとBクラスとの距離は何もしていないFig. 2の左上図と比べてお互いがより離れています。また、AとB以外にCも含めて本手法を用いると、Fig. 2の右下図のようにCも含めてバランスよく配置されるようになっています。ここも言葉だとイメージしにくいので図解をみてもらったほうが早いと思います。
今回の過程は、所謂data augmentationをしたようになっていると思ったのですが、著者に直接確認したところdata augmentationのように元画像と意味的には同じ特徴量を生成しておらず、どちらかというと新規に学習データとして画像データが生み出されている感覚だとのことでした。一般に教師データが増えるほど精度は向上するので、このようなアプローチは非常に興味深いところです。
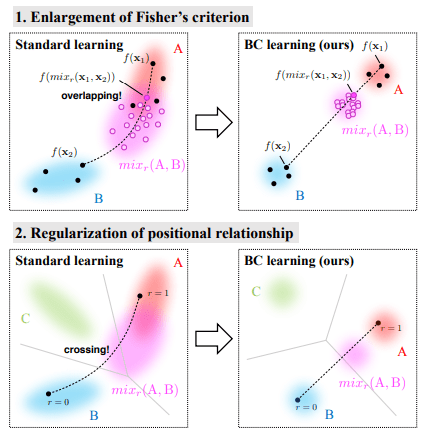
Fig. 2 それぞれのクラスの固まり方
本学習方法では特徴量分布に制約を課す能力があるようで、これは通常の学習方法ではできません。上図は特徴量空間内のクラス分布を示しており、黒い破線はデータを合成する0~1の割合に応じて特徴量が移動する軌跡を表しています。上段2図では画像を合成した特徴量がマゼンタカラーで表されており、本学習方法を使うと各クラスと重複する部分が少なく、うまく分かれていることがわかります。また、3クラス以上で本学習方法を使うと、合成されていない残りの1クラスの境界線もはっきりと分かれていることがわかります。
※引用元:https://arxiv.org/abs/1711.10284
Fig. 3ではさらに多クラスで同様の処理をした場合、特徴量が空間的にどのように配置されているかが図示されていますが、本手法を用いた方が各クラス内の特徴量の分散が小さく、固まって配置されていることがわかります。しかし、合成する際は異なるクラスの画像を3つ以上合成すると精度が悪化することや、CNNの入力層付近で合成しないと精度が悪化することもわかっているようです。これはCNNの構造的に深度が大きくなると空間的な情報や、意味的な情報の両方を表すようになるため、入力層以外で合成することは機械からすると元の画像の情報とは異なる意味合いを捉えてしまっているかもしれないとのことです。
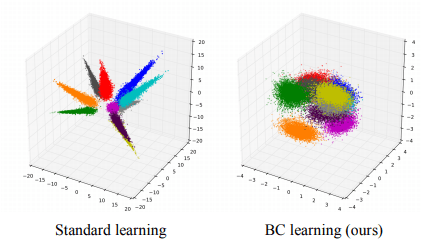
Fig. 3 各クラスの特徴量の固まり方の違い
3次元PCAという手法を用いた特徴量分布を可視化したものになります。
本手法を使うと右側のようにクラス毎の特徴量分布が集約していることがわかります。
※引用元:https://arxiv.org/abs/1711.10284
一般的に画像分類を行う場合でも各クラス内の特徴量の散らばりを小さくするよう学習をしていきますが、本手法を用いるとその傾向がより顕著になるため、モデル精度を向上させることに繋がっているのではないかと思われます。次回のコラムでご紹介予定ですが、弊社では自動販売機にどんな商品が何個入っているかをディープラーニングで機械的に抽出しようと試みているのですが、自動販売機の商品を屋外の少ないサンプルの中で分類する必要があり、多クラス分類の精度向上は気になるトピックでもあります。通常はクラスが増えれば誤分類する割合は増加していく傾向にありますが、クラス毎の特徴量が空間的にきれいにまとまっていく本手法を使えば、分類精度を安定的に向上させる有効な手段になるかもしれません。一般的に精度向上の手法としては、CNNモデルの選択/調整やfine tuning(※15)、data augmentationの条件検討等が王道でしたが、本手法のように元の学習データを増やさなくても画像を合成することで、新たな学習データを準備できるという点においては、学習データが少ない事例とは非常に相性がよいと期待が持てました。
こういった研究成果は聞いているだけでも面白いですが、その知見をビジネスでどうやったら活かせるのか?を考えることも面白いところですので、今回のような機会を逃さないようにしていきたいですね。実際に足を運び、調べて、見て、聞いていくことが大事だと思いますので、今後も積極的に技術収集を進めていきたいと思います。
※1 マーケティングリサーチ:企業のマーケティング課題を解決するために、行う調査・分析のこと。インテージは国内No.1*のマーケテイングリサーチ会社です。
*Global Research Business Network調べ(グループ連結売上高ベース)
※2 個人メディア視聴履歴:弊社サービスである「Media Gauge® TV」では日本全国の120万台のスマートテレビと62万台の録画機から視聴ログデータを収集しています。
https://www.intage.co.jp/service/platform/mediagauge-tv/
※3 画像分類:与えられた複数カテゴリーの画像を機械的に分類すること。
※4 CNN:Convolutional Neural Networkの略。人間の視覚野の構造からアイデアを得て作られたニューラルネットワーク。特徴量の畳みこみを行うConvolutional Layerと情報の抽出を行うPooling LayerをNeural Networkに導入したもので、上下左右を加味した特性を扱うことができます。画像を扱う問題で利用されることが多いです。
※5 data augmentation:学習データを水増しすること。画像のdata augmentationでは、角度を変えたり、左右を反転させたり、輝度を変えたりする手法がよくとられます。
※6 drop out:正則化のテクニックの一つ。ニューラルネットの訓練中、一部のニューロンを無視して学習を行います。
※7 batch normalization:各層で活性化関数を実行する直前に、各ユニットの出力を一定の割合で分割した学習データごとに正規化(normalization)した新たな値で置き換える手法。内部の変数の分布(内部共変量シフト)が大きく変わるのを防ぎ、学習が早くなる、過学習が抑えられるなどの効果が得られます。
※8 汎化性能:あるものに共通する性質などを汎用的に見出す性能のこと。機械学習による画像分類おいては、学習用に与えられた画像以外の未知の画像も適切に分類しなければならないため、高い汎化性能が求められます。
※9 過去論文:Learning from between-class examples for deep sound recognition. In ICLR, 2018.
※10 ImageNet: 1400万枚以上の画像にクラス名が付与されている画像データベース。
ImageNetのデータセットを題材とした画像判別のコンペティションILSVRC(ImageNet Large Scale Visual Recognition Challenge)が毎年開催されており、近年のCNNの目覚ましい発展はその結果から見て取れます。画像分類のベンチマークとしてよく使われています。
※11 CIFAR-10:飛行機や猫など10種類のクラスの画像6万枚のデータセット。画像分類のベンチマークとしてよく使われています。
※12 One-hot label:1つの項目だけHighであり、他の項目はLowであるラベルのこと。統計的な解析にカテゴリーデータを用いる場合、ダミー変数化してOne-hot labelにすることで、上手く扱えるようにします。例えば、イヌとネコの画像群から”イヌである”という画像を学習したい場合は”イヌ:1、ネコ:0”というようにダミー変数化します。
※13 正規化:データを一定のルールに基づいて変形すること。統計学や機械学習の分野では、正規分布(0,1)に標準化することが多く、正規化というだけでそのことを指すこともあります。
※14 特徴量:ここではCNNの中間層の出力値のこと。CNNの中間層では画像の何らかの特徴を扱っています。特徴量という言葉は、使う人や文脈によって指すものが変わることが多いです。
※15 fine tuning:学習の初期段階で似たタスクをこなすニューラルネットワークの重みを再利用する手法。学習時間の短縮、汎化性能の向上、精度の向上などが期待できます。

本レポートの著作権は、株式会社インテージが保有します。本レポートの内容を転載・引用する場合には、「インテージ調べ」と明記してご利用ください。お問い合わせはこちら
【転載・引用に関する注意事項】
以下の行為は禁止いたします。
・本レポートの一部または全部を改変すること
・本レポートの一部または全部を販売・出版すること
・出所を明記せずに転載・引用を行うこと
・公序良俗に反する利用や違法行為につながる可能性がある利用を行うこと
・自社商品の宣伝・広告・販促目的での使用はご遠慮ください。
※転載・引用されたことにより、利用者または第三者に損害その他トラブルが発生した場合、当社は一切その責任を負いません。
※この利用ルールは、著作権法上認められている引用などの利用について、制限するものではありません。





