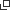
インテージ×XICA Magellanで切り拓く
汎用的なマーケティング・ミックスモデルの実現
マーケティング施策の費用対効果や最適な費用配分を検討するためのアプローチであるマーケティング・ミックスモデリング(以下、MMM:Marketing Mix Modeling)。インテージではこれまでお客様へ向けてMMMのサービス展開を進めてきたが、ここにきて新たな展開を迎えている。
2018年1月よりインテージと株式会社サイカの共同研究がスタートした。この取組みは、インテージが保有する各種データとサイカのMMM作成ツールである『XICA Magellan』を連動させ、短期的・汎用的なマーケティングPDCAの実現を目指すものである。一方で、MMMはそのモデルが持つ性質上、正しい理解の上でモデルを構築していかないと、効果を見誤ったり、効率の悪い配分を導く危うさを有している。
本記事では、MMMの可能性と課題をビジネス的視点・学術的視点から、慶應義塾大学 星野 崇宏教授×サイカCEO平尾 喜昭氏×インテージ中野 暁の三者対談により明らかにしていく。
※ マーケティング・ミックスモデリングの説明はこちらを参照ください。

(左から、インテージ中野 暁;慶應義塾大学 星野 崇宏;サイカ 平尾 喜昭)
―――――顧客の素早いマーケティングPDCAの支援に向けてMMMを汎用化していく
中野:デジタルマーケティング領域を中心に意思決定のスピードが早くなっています。それに応じて、施策とその効果の検証を行うMMMの役割も変わってきたように思います。これまでのMMMは、モデリング手法の煩雑さから、ある程度長期的な期間を想定した上で、顧客に応じてオーダーメイドで提供する形式が主流でした。インテージでもデータサイエンティストの専門集団がその都度モデルを構築しながら対応してきました。しかし、現代のビジネス環境ではそれだけでは遅い。日次・週次単位の施策に対して、その効果を捉え、日々の意思決定を改善していけるモデルが求められているように思います。
平尾:サイカではXICA Magellanを運用しながら、仮説を持つマーケッターがライト、かつ、コンスタントに分析できる環境作りを目指してきました。プロはプロのデータ分析法がある中で、恒常的な分析は仮説をもっているマーケッター自身が行えるようにしたい。マーケッターは日々、ベターな決断をし続けなくてはなりません。そのためには、短期的な試行錯誤の回数を増やしていくことが必要です。回数を重ねるうちに、目の前の観測データがより深く見えるようになる。私はよく「分析の民主化」という言葉を使いますが、ライトな分析を繰り返していけば、マーケッターのリテラシーがあがり、より発展的な分析にもつなげていくことができます。これまでサービスを導入してきた成果として、こうしたマーケッター向けの環境構築について、十分なニーズがある事を掴んでいます。
星野:「分析の民主化」は良い言葉ですね。データサイエンティストやコンサルなど専門家のみがデータにアクセスするのではなく、社内各部署、経営陣、場合によっては関係各社ともその知見が共有されることで、どの部分が問題となっているか、改善のために何が必要か、モニタリングのためにどんなデータを集めるのがよいかの理解が進み、よいサイクルができると思います。
―――――しかし、注意しなくてはいけないことも
中野:一方で、「なぜ今までMMMが汎用的・自動的になりにくかったのか?」という観点にも注意する必要があると思います。MMMはそのモデルの特性上、変数の数が多い・変数間の相関が高過ぎる・適切な構造が設定されない等の理由で、効果の推定がうまくいかないケースが発生しやすいモデルだと認識しております。一つのポイントは、マーケッターがライトな分析をいかに堅実・安全に行っていくかにあるように思います。
星野:そうですね。ライトな分析で陥る問題のパターンというのは実は共通しています。例えば、広告効果推定における「負の係数問題」があります。これは欧米でも昔から知られていた問題で複数メディアへの広告出稿費で売り上げを説明するような回帰分析を実行すると、どれかのメディアの係数が負になることが多い、という問題です。Naikら(2007)の研究が有名ですが、彼らがカローラのクロスメディア・キャンペーンの分析を行ったところ、クロスメディアの係数が意味不明な負の係数になりました。
日本でもこの問題はネット広告が出る前から言われており、ネット広告を含めた分析を行っても同様によく生じる問題です(井上, 2000; 照井・大西, 2003; 星野, 2008)。なんといっても屋外広告やネット広告を投下するほど売り上げが落ちる、というのは直観的でないですよね。この手の問題は非常によく起きるのに、皆だいたいその場しのぎの対処、例えば負になった係数をゼロに固定するとか、全体の係数に近づけるとかいったことをするということでも共通しています(笑)
中野:なぜこのような問題が起こるのでしょうか?
星野:本質的には、広告出稿の行われ方と消費者行動のメカニズムを無視したブラックスボックス的な解析に起因するものだと思います。通常、週次や月次などの集計済の時系列データを基にしてMMMを構築する場合、広告費(入力)と売上(出力)の関係について回帰分析のような出力を入力で説明する方法が用いられますが、最近ではカーネル回帰やディープラーニング等の機械学習的アプローチも利用されますね。いずれにしても、広告費と売上というデータだけ見て推定しようとすると、それはブラックボックス的な解析にあたります。
しかし、本来そのデータの背景には、「広告に接触して認知して購買する」という消費者行動のプロセスがあります。それを無視して分析すると、消費者の実態にそぐわない誤った結果を導くことがあります。例えば新しい携帯電話の広告を見て、「いいな」と思っても、実際にニーズが発生するのは携帯の買い替えのタイミングですよね。即時的に効く広告もありますが、名前を憶えてもらったりイメージを高める広告も多いですから、それらの配分となるとラグなどいろいろなことを考慮しないといけません。
中野:この問題を回避していくためにはどうすればよいでしょうか?
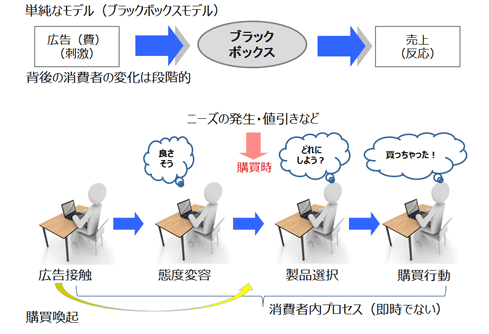
星野:「段階的にプロセスを評価していくこと」がポイントでしょう。広告効果のモデルでいうと、ARF(Advertising Research Foundation; 米国広告研究協会)のモデルが有名ですが、消費者の広告接触から購買までには、媒体到達、広告到達、広告コミュニケーション、購入、購入後といったプロセスがあります。このプロセスを評価していくための仕組みとデータをいかに揃えられるかが、実務的には重要になると思います。
勿論、入力と出力の集計時系列データだけの分析でも、「内生性バイアス:回帰モデルの前提条件が成立しないケース」「時系列構造」「広告の忘却と摩耗効果」などを考慮し、モデルに組み込むことによって適切な推定をする方法はマーケティングサイエンスの専門家ならば知っています。しかし、それには高度な分析スキルが要求されます。実務的に短期・高速なPDCAをライトに回していくのであれば、段階的な評価が可能な変数をきちんと定義して、その効果を紐解いていくことに注力する方が健全に思います。
平尾:「段階的」という考え方には大変共感します。我々もXICA Magellanを開発する時に、段階的な効果を正しく評価できる手法を、いかにユーザー・フレンドリーに作り上げられるかを意識してきました。また、実際に運用する際に、それぞれの効果を一つずつ着実に納得感をもってお客様に読み解いて頂くことが、現場での有用性につながっていると感じています。少し話はそれますが、昨今のAIブームで、ややおかしな流れにいっている、と思うことが時々あります。AIに全て丸投げすると、何でも解決してくれるかというとそうではない。ごちゃっと全て見てしまうと、どこかが正しくて、どこが間違っているかがわからなくなってしまうというのは、AIでも同じだと思います。
星野:そうですね。特にマーケティングのような人の行動や心理を扱う分野では注意が必要です。私は今、理研のAIPセンター(人工知能の研究センター)のチームリーダーを兼任していますが、世の中ではAIは過大評価され過ぎていて、AIや機械学習でデータ分析が正しくできるという誤解があります。これは専門家の間でも問題になっていて「出来る範囲を明確に定義しながら着実に進めていこう」という注意喚起が必要という意見で一致しています。AIは今後の有用な手段であることに変わりはありませんので、夢ばかり拡がるが実情が伴わず、結果として途端に皆さんの熱が冷めていくという流れは避けなくてはいけません。
中野:MMMも同じですね。色々なデータをシステムに投入すると、何か良いことがわかりそう・・・と思うかもしれませんが、実は大事なのは、「段階的に消費者行動を捉えてマーケッターが分析結果を細かく理解しながら、進めていくこと」というわけですね。ただし、本来そうした作業は手間暇がかかるものであり、「短期的」、「高速PDCA」、「汎用化」、「自動化」といった考え方とは相反します。
―――――「汎用性・高速性」と「段階的な消費者理解」を共に実現していく、そのポイントは?
中野:インテージとサイカの取り組みによって、ライトなユーザーが日々のマーケティング活動に使えるMMMの構築を目指した場合、2つのポイントがあるように思います。
一つは、XICA Magellanの操作性。私もXICA Magellanを使ってみて感激したのですが、推定結果がおかしい時に出るアラート機能が大変充実している。データ分析のプロであればアラートがなくても気づくのですが、そうでない人でも使える汎用化を目指す場合にはいかに間違いに気づかせるかが重要なポイントになります。
もう一つは、変数のプリセット。インテージは、SRI®やSCI®といった購買データ、i-SSP®やMedia Gauge®といったメディアデータを保有しています。また、アンケートをかけて消費者の意識をとっていくこともできます。これらによって一定の段階的な分析軸を築き、そこにお客様側のデータを掛け合せていくことで、より頑健なモデルを構築していけると思います。
また、最近は、「INTAGE connect®」のように外部のBIツールとのデータ接続にも力を入れております。XICA Magellanとも接続しましたので、データの準備や整形に時間を割かずとも、気軽に、日次・週次で更新されたデータを参照することが可能です。
平尾:そうですね。
一つめの操作性について、中野さんが仰ったXICA Magellanのアラート機能ですが、特に「分析結果の精度向上」と「予算配分のシミュレーション」において、ユーザーがデータ分析を正しく進められるよう適切なアラートを出すことを意識しています。
前者の「分析結果の精度向上」は、まさに「汎用性・高速性」と相容れないもので、通常であれば、専門的な知識と膨大な工数を要する作業となります。しかしXICA Magellanであれば、精度を低下させる原因となっている箇所にアラートが表示されるため、ユーザーはどこを直すべきかを一目で把握することができます。さらに、その改善もユーザーインターフェース上で容易に行うことができます。
後者の「予算配分のシミュレーション」においても、現実的ではないシミュレーション結果にならないよう、ユーザーがシミュレーションの設定を行う際に基準にできる数値がXICA Magellan上で提示されるようになっています。
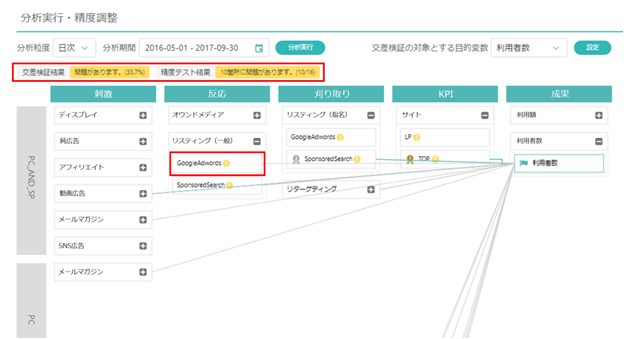
XICA Magellanの精度調整機能。赤枠で囲まれた箇所のように、パス解析の精度低下の原因になっている箇所を一目で把握することができる。
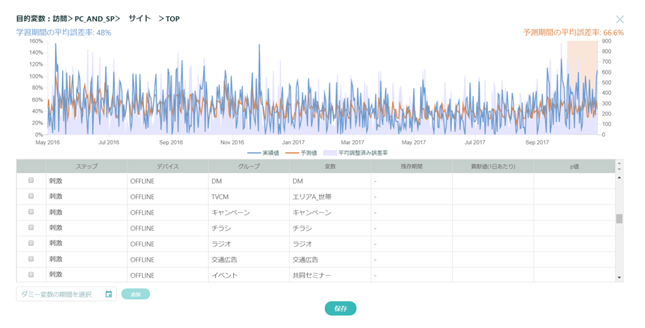
精度低下の原因になっている箇所をユーザーインターフェース上で改善することができる
星野:XICA Magellanのアラート機能は、無理のない範囲で推定を行うことに配慮されているように思います。一定の妥当性が担保された結果に、分析者の知見を入れ込んで、解釈を進めていくとより良いと思います。
平尾:二つめの変数のプリセットですが、これも大変重要になります。顧客側で既に持っているデータだけでMMMをやろうとすると、データが足りずに、痒いところに手が届ききらなかったという事例もありました。特に、ナショナル・リテイルの分野は、根が深いです。インテージさんのSRIやSCIを使うと、購買KPIを定められるので、活用の幅がぐんと拡がることに期待しています。また、過去にはオンライン上のデータは入手できるけれども、オフラインのデータに乏しいといった事例もありました。オンライン・オフラインのデータを共に充実させていけることにも可能性を感じています。
「段階的」の話ともつながりますが、「データは色々集まったけれど、何か使えないか」というスタンスで取り組むと、実はうまくいかないといったこともありえます。「たまたまいい結果が出た」ではなく、「このデータをこういう形ならば堅牢に使える」という確証をPDCAの中で積み上げていくことが必要だと思っています。
星野:データはそれぞれバイアス(偏り)を持っているので、その傾向を理解して使っていくことが、正しい結果を導くことにつながりますね。インテージさんの提供するパネルデータは、母集団や測定のカバレッジといった調査設計を有するので、結果に対する説明性に優れる強みがあります。また、市場全体を捉えられるので、自社と競合の比較にも使えて良いですね。私も以前から、既存顧客と競合他社を利用している(潜在)顧客は大きく異なる(専門的には選択バイアスがある)ので、自社でもつデータがいくら膨大であっても、潜在顧客に有効なマーケティング施策のための解析は自社データだけではできないこと、一方、いくつかの重要な情報を外部データから得ていればそれが可能になるといった研究を行ってきました(例えば、星野, 2013; 新美・星野, 2017)。自社データだけでわからない情報を組み込んでいくことも正しい判断には必要です。
中野:そうですね。弊社のパネルデータというのは、調査目的とその目的を実現するための調査設計に基いてデータを「集める」形で取得し、日々の運用で品質管理しているデータになりますので、市場の動きを説明するのに使いやすいかと思います。一方で、弊社は今、新しい種類のデータの活用、具体的には、自動的に「集まる」形で取得されたビッグデータ(全数系のビッグデータ)にも力を入れています。例えば、全国50万台のスマートテレビの視聴ログデータであるMedia Gaugeもその一つです。こうしたビッグデータに対して、パネル管理で培ってきた設計ノウハウを適用し、使える形に価値化していくという動きが今後も多種類のデータで進んでいきます。
その次のフェーズは、各データを組合せて価値を出していく所を見越しており、MMMのような方法論も組合せていくと、ますます出来ることが拡がりそうで、楽しみですね。
―――――最後に
中野:最後にお二人から一言ずつ、頂きたいと思います。
平尾:これまでの広告分析はログで繋がるオンライン上の分析に終始してきましたが、それでは不十分であることに企業は既に気付き始めており、これからは、ログでは断絶されてしまうオフラインの領域まで広げてモデル化して分析することが当たり前に求められるようになってゆくでしょう。それを可能にするためには、短期的・汎用的なマーケティングPDCAを実現する推計ツールが必須であり、今回のインテージさんとの取り組みは、今後の広告業界にとって非常に意義深いものになると確信しています。
しかし忘れてはならないのが、どんな分析結果であれ、それは意思決定の材料に過ぎず、最終的に意思決定をするのは人である、ということです。人が分析に操られるのではなく、分析を用いて人がより深く思考し、意思決定できる世界を作っていきたいと思います。
星野:データが膨大かつ低コストで得られる時代において、「分析の民主化」というコンセプトは非常に重要ですが、ブラックボックス型の分析では必ず落とし穴にはまります。サイカさんのツールはその問題を踏まえて作成されており、そこにインテージさんが作成されている市場反映性のある様々なデータが加わることで、マーケティング実務から経営意思決定に至るまで様々な示唆が得られることが期待できると思いました。
中野:私は、本取組みに端を発して、様々なデータが有機的につながる世界に大変期待を抱いております。一方で、そのデータが説明する範囲や、解析手法が持つ特性と限界を把握していかないと、話を間違った方向に進めてしまうことになりかねない。あるいは、AIや自動化が進むと、間違いにすら気づかないかもしれない。
本日のお話は、短期的・汎用的な世界を目指す中で、「人」の要素も入れながら、段階的に着実にデータを捉えていこうというもので、納得感がありました。ぜひ今後はお客様と共に実際の課題に取り組み、成功事例を築いていきたいですね。
本日はありがとうございました。
星野 崇宏
(慶應義塾大学経済学部教授/理研AIPセンターチームリーダー)
2004年東京大学大学院博士課程修了。博士(学術、経済学)。04年統計数理研究所助手、08年名古屋大学大学院経済学研究科准教授などを経て15年より現職。第13回日本学術振興会賞受賞。2017年日本統計学会研究業績賞受賞。行動経済学会常任理事。日本マーケティング・サイエンス学会理事。日本行動計量学会理事。応用統計学会理事。社会調査協会理事。

平尾 喜昭
(株式会社XICA 代表取締役CEO)
2012年慶應義塾大学卒業。父親の倒産体験から「世の中にあるどうしようもない悲しみを無くしたい」と強く思うようになる。大学在学中に統計分析と出会い、2012年に株式会社サイカを創業。 同社は“すべてのデータに示唆を届け、すべての人に幸福を届ける”というミッションのもと、業務ニーズに特化した分析アプリケーションを開発する。現在はマーケティング統合分析ソリューション「XICA magellan (マゼラン)」を主軸にプロモーション領域において急成長を続けている。

中野 暁
(株式会社インテージ)
大学院で数理統計学を専攻後、株式会社インテージ入社。メディア領域を主として、シングルソースパネルの設計/品質管理、データ解析、研究開発などに従事。現在は全数系ビッグデータ("集まる"データ)の価値開発事業を担う。現在、慶應義塾大学 産業研究所 共同研究員、筑波大学大学院 システム情報工学研究科 博士後期課程 在学。

参考文献
- Naik, P.A., Schultz, D.E., and Srinivasan, S. (2007) “Perils of Using OLS to Estimate Multimedia Communications Effects”, Journal of Advertising Research, 47(3), 257-269.
- 井上哲浩 (2000) “メディア・プランニング・モデル:広告四媒体効果算定および最適予算配分”,日経広告研究所報, 34(5), 9-15.
- 照井伸彦・大西浩志 (2003) “ブランド知名率に対するメディア・ミックス広告効果の測定:階層的ベイズ回帰モデルによる縮約推定の適用”, マーケティングサイエンス, 11(1), 43-59.
- 星野崇宏 (2008), “ブランドイメージに関する広告政策を策定するための階層ベイズ的な選択モデルとその応用”, マーケティングサイエンス, 15(1), 27-44.
- 星野崇宏(2013) “継続時間と離散選択の同時分析のための変量効果モデルとその選択バイアス補正:Webログデータからの潜在顧客への広告販促戦略立案”, 日本統計学会誌, 43, 41-58.
- 新美潤一郎・星野崇宏(2017), “顧客行動の多様性変数を利用した購買行動の予測”, 人工知能学会論文誌, 32(2), B-G63_1- 9.